16.6.2026
Autonome Feature-Entwicklung mit zwei KI-Modellen
Autonome Feature-Entwicklung: Zwei KI-Modelle spezifizieren, bauen, testen und reviewen ein Feature von der Spec über TDD bis zum geprüften Pull Request.
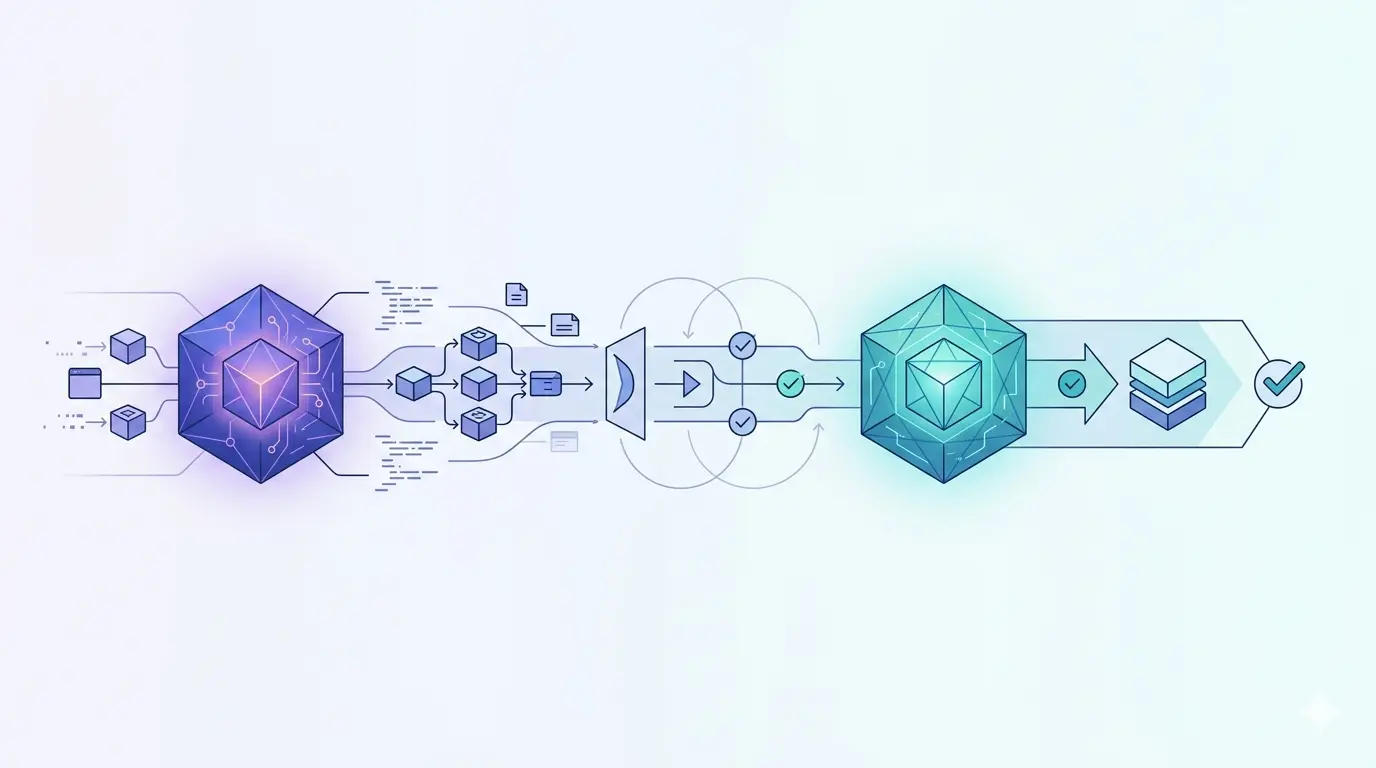
Autonome Feature-Entwicklung: Wie zwei KI-Modelle Software bauen und prüfen
Zuletzt aktualisiert: 16. Juni 2026
Kurz gesagt (TL;DR)
Autonome Feature-Entwicklung bedeutet: Du beschreibst ein Feature einmal als Datei, und zwei verschiedene KI-Modelle übernehmen den Rest. Ein Modell baut (Claude Code), ein zweites prüft (das Codex-Plugin von OpenAI). Spezifikation, Plan, Code, Tests und Reviews entstehen eigenständig. Am Ende stehen geprüfte Pull Requests, die du nur noch mergst. Der Aufwand verschiebt sich vom Tippen zum Spezifizieren und Entscheiden, ersetzt wird der Entwickler nicht.
Was bedeutet autonome Feature-Entwicklung?
Autonome Feature-Entwicklung beschreibt einen Workflow, in dem du genau ein Artefakt lieferst, ein sogenanntes Feature-File, und zwei KI-Modelle daraus eigenständig spezifizieren, planen, programmieren, testen und reviewen. Der Mensch liefert die Absicht, die Maschine liefert geprüfte Pull Requests. Du reviewst und mergst danach nur noch.
Das Entscheidende ist die Rollentrennung. In diesem Aufbau ist Claude Code der Builder: das Modell, das spezifiziert, plant und Code schreibt. Das Codex-Plugin von OpenAI ist der Reviewer: ein zweites, anderes Modell, das jede Stufe gegenliest. Das Feature-File ersetzt dabei den klassischen interaktiven Dialog. Wo ein Assistent dich sonst Schritt für Schritt nach Anforderungen fragt und Freigaben einholt, ist hier das Feature-File gleichzeitig Input und Freigabe. Jede Entscheidung leitet der Agent daraus und aus der bestehenden Codebase ab.
Was genau ist ein Feature-File?
Ein Feature-File ist ein High-Level-Auftrag, der mehrere Teilfeatures auflistet: mit Motivation, konkreten Architektur-Andockpunkten (inklusive Datei-Referenzen), empfohlener Reihenfolge, Abhängigkeiten und einer Definition of Done pro Teilfeature. Es ist nicht die detaillierte Spec eines einzelnen Features, sondern die Ebene darüber, der Master-Plan oder das Backlog.
Ein Teilfeature ist dabei die Einheit, die genau einen Pull Request ergibt. Es wird so geschnitten, dass es für sich lauffähig und testbar ist. Genau das leistet die Definition of Done im Feature-File: Sie macht jeden Teilauftrag prüfbar, bevor eine einzige Zeile Code entsteht.
Warum zwei KI-Modelle statt einem?
Weil ein Modell, das seinen eigenen Code im selben Kontext reviewt, frühere Annahmen ungeprüft übernimmt. Dieser Effekt heißt Context Rot: Je länger ein Modell in einem Gesprächsverlauf steckt, desto stärker verfestigen sich einmal getroffene Entscheidungen, auch die falschen. Ein frischer, andersartiger Reviewer bricht diesen Tunnelblick auf.
Technisch könnte ein einzelnes Modell beide Rollen übernehmen. In der Praxis ist das nicht empfehlenswert. Zwei verschiedene Modelle (hier Claude als Builder, ein Codex-Modell als Reviewer) haben unterschiedliche Trainingsdaten, unterschiedliche Schwächen und unterschiedliche blinde Flecken. Was das eine übersieht, fällt dem anderen auf. Das ist derselbe Gedanke wie beim Vier-Augen-Prinzip in menschlichen Teams, nur dass beide Augenpaare hier Maschinen sind. Genau diese Reibung zwischen zwei Modellen erzeugt die Qualität, die einen Workflow erst autonom tragfähig macht.
Welche Tools brauchst du für diesen Workflow?
Du brauchst zwei KI-Werkzeuge und eine kleine technische Grundausstattung. Claude Code übernimmt das Bauen, das Codex-Plugin das Reviewen. Dazu kommen ein ChatGPT-Abo oder ein OpenAI API Key, Node.js (ab Version 18.18) und die Codex CLI. Optional erzeugst du dein Feature-File aus einem Design-Tool.
Die Review-Schritte laufen nicht über einen Klick, sondern über die Codex CLI, konkret über das Skript codex-companion.mjs, das per Bash aufgerufen wird. Das Modell dahinter ist standardmäßig das, was in der Codex-Konfiguration als Default eingetragen ist (in meiner Einrichtung ein aktuelles Codex-Modell mit hohem Reasoning-Aufwand, authentifiziert über ChatGPT). Für das Feature-File selbst kannst du ein UI in Google Stitch oder Figma entwerfen und es der KI übergeben, etwa per Export oder über den MCP-Server von Stitch.
| Werkzeug | Rolle | Voraussetzung |
|---|---|---|
| Claude Code | Builder (Spec, Plan, Code, Tests) | Anthropic-Zugang |
| Codex-Plugin (OpenAI) | Reviewer (Spec, Plan, Code) | ChatGPT-Abo oder OpenAI API Key |
| Codex CLI / Node.js | führt die Reviews aus | Node.js ab 18.18 |
| Google Stitch oder Figma | erzeugt das Feature-File aus einem Design | optional |
Tabelle: Werkzeuge und Voraussetzungen für den autonomen Feature-Workflow. Stand: Juni 2026.
Wie sieht der Ablauf Schritt für Schritt aus?
Jedes Teilfeature durchläuft sieben Phasen, von der Spec bis zum sauberen Pull Request. Spec und Plan werden je maximal zwei Runden lang reviewt, der finale Code-Review läuft, bis keine Issues mehr offen sind. Der Endzustand ist immer derselbe: ein Pull Request ohne offene Reviewer-Befunde, bereit zum Merge durch den Menschen.
Feature-File
└─► pro Teilfeature (in Reihenfolge / nach Abhängigkeiten):
A. Spec schreiben (Builder)
B. Spec-Review-Schleife (Reviewer) ── max. 2 Runden
C. Plan schreiben (Builder)
D. Plan-Review-Schleife (Reviewer) ── max. 2 Runden
E. Umsetzen mit TDD (Builder)
F. Pull Request erstellen
G. PR-Review-Schleife (Reviewer) ── bis 0 Issues
└─► PR fertig → nächstes Teilfeature oder StopDieser Ablauf ist bewusst linear und prüfbar. Erst wenn eine Phase sauber abgeschlossen ist, beginnt die nächste. Abhängige Teilfeatures werden nie vor ihrer Vorbedingung gebaut. Im Folgenden gehe ich die drei Blöcke (Spec, Plan, Umsetzung plus Review) im Detail durch.
Phase A und B: Spec schreiben und prüfen
In Phase A erzeugt der Builder eine fokussierte Spec für genau ein Teilfeature: Ziel, Schnittstellen, konkrete Datei-Andockpunkte und Abnahmekriterien. Designentscheidungen, die das Feature-File offen lässt, trifft der Agent selbst mit begründetem Default und hält sie unter Annahmen fest. Danach beginnt die Spec-Review-Schleife mit hartem Limit von zwei Runden.
Warum nur zwei Runden? Weil die ersten beiden Durchläufe die meisten echten Lücken abfangen, danach sinkt der Nutzen stark. Das Limit verhindert Endlosschleifen, in denen das Modell endlos an Formulierungen feilt, ohne dass die Qualität steigt. Verbleibende, bewusst nicht umgesetzte Punkte werden als kurzer Vermerk in der Spec festgehalten, statt sie immer wieder neu zu diskutieren.
Phase C und D: Plan schreiben und prüfen
Der Plan baut auf der finalisierten Spec auf und zerlegt das Teilfeature in kleine, testgetriebene Aufgaben: jeweils ein fehlschlagender Test, dann die Implementierung, dann grün. Jede Aufgabe nennt exakte Datei- und Test-Pfade sowie Verifikationsbefehle. Auch hier folgt eine Review-Schleife mit maximal zwei Runden, diesmal mit Fokus auf Vollständigkeit gegenüber der Spec, falschen Datei- oder Typ-Annahmen, fehlenden Tests und riskanten Schritten.
Der Plan-Review ist die letzte günstige Gelegenheit, Fehler zu finden. Ein Denkfehler, der hier auffällt, kostet eine Korrektur im Text. Derselbe Fehler, erst im Code entdeckt, kostet eine Korrektur in mehreren Dateien plus Tests. Diese Verschiebung des Prüfaufwands nach vorne ist der Kern von Spec-Driven Development.
Phase E, F und G: Umsetzen, PR und Review bis null Issues
In Phase E setzt der Builder den Plan Aufgabe für Aufgabe um, strikt nach Test-Driven Development: Test zuerst, kleine Schritte, häufige Commits. Vor dem Pull Request müssen alle Verifikationsbefehle grün sein (Typprüfung, Linting, Tests), mit gezeigtem Output und ohne Behauptungen ohne Beleg. Dann erstellt der Agent über die GitHub CLI (gh) den Pull Request gegen den Hauptbranch.
Phase G ist der eigentliche Code-Review und hat bewusst kein festes Rundenlimit. Der Reviewer liest den vollständigen Diff, der Builder arbeitet jeden Befund ein, verifiziert erneut und schickt zurück in den Review. Das wiederholt sich, bis eine Runde null Issues meldet. Ein Notausgang verhindert das Festfahren: Tauchen nach drei aufeinanderfolgenden Runden weiterhin Befunde auf oder kehrt dasselbe Finding zweimal wieder, stoppt der Agent und legt den Pull Request mit den strittigen Punkten dem Menschen vor.
Warum meldet ein Code-Review meiner Spec null Fehler?
Weil eine Spec aus Text besteht und ein reiner Code-Reviewer nach Code-Defekten sucht. Findet er keinen Code, meldet er null Issues, nicht weil das Design fehlerfrei ist, sondern weil es nichts zu prüfen gibt. Das ist eine der häufigsten Stolperfallen beim Aufsetzen solcher Workflows.
Die Lösung ist eine bewusste Werkzeugwahl. Für Spec und Plan (also Prosa und Design) nutzt du ein Design-Review mit explizitem Fokus-Text, der das Modell anweist, das Design zu bewerten: Vollständigkeit, Widersprüche, unklare Annahmen, Sicherheits- und Betriebsrisiken, Testbarkeit. Für den Pull Request (also echten Code-Diff) nutzt du den reinen Code-Reviewer, denn dort liefert er seinen eigentlichen Wert. Wer beide Modi verwechselt, bekommt entweder Scheinsicherheit (null Issues auf einer Spec) oder verschenkt Tiefe.
| Phase | Was wird geprüft? | Review-Typ | Schleifen-Limit |
|---|---|---|---|
| B (Spec) | Prosa, Design | Design-Review mit Fokus-Text | max. 2 Runden |
| D (Plan) | Prosa, Design | Design-Review mit Fokus-Text | max. 2 Runden |
| G (Pull Request) | echter Code-Diff | reiner Code-Review | bis 0 Issues |
Tabelle: Der passende Review-Typ je nach geprüftem Artefakt.
Wie startest du den ganzen Workflow mit einem einzigen Satz?
Indem du den Ablauf als Markdown-Datei im Repository ablegst und aus der Instruktionsdatei deines Agenten darauf verlinkst. Bei Claude Code ist das die CLAUDE.md, bei Codex die AGENTS.md. Der Agent liest diese Instruktion bei jedem Start und folgt dem hinterlegten Ablauf, ohne dass du ihn jedes Mal neu erklärst.
Damit wird aus einer komplexen Prozedur ein wiederholbarer Standard. Du sagst sinngemäß nur noch: Setze das Feature aus dieser Datei um. Den Rest, also die Phasen A bis G, das Schleifen-Limit und die Werkzeugwahl, holt sich der Agent aus der verlinkten Anleitung. Diese Selbstreferenz ist der Hebel, der den Workflow im Alltag tragfähig macht: Die Disziplin steckt im Repository, nicht in deinem Gedächtnis.
Wie entsteht ein Feature-File aus einem Figma- oder Stitch-Design?
Du baust das gewünschte UI in Google Stitch oder Figma und übergibst es der KI, etwa als Export oder über den MCP-Server von Stitch. Die KI leitet daraus ein Feature-File ab, also Teilfeatures, Andockpunkte und eine Definition of Done. Dieses File durchläuft anschließend selbst zwei Review-Runden, bevor die Umsetzung startet.
Der Vorteil: Du arbeitest dort, wo Produktentscheidungen ohnehin fallen, im visuellen Entwurf. Statt Anforderungen in Prosa zu formulieren, zeigst du das Ziel und lässt die KI die strukturierte Spezifikation daraus ableiten. Das senkt die Hürde für nicht-technische Beteiligte und hält den Input bewusst klein, ganz im Sinne des Grundprinzips: ein einziges Artefakt vom Menschen, alles Weitere von der Maschine.
Ist die Methode an einen bestimmten Tech-Stack gebunden?
Nein. Der Ablauf aus Feature-File, Spec, Plan, TDD und Pull-Request-Review ist stackunabhängig. Er funktioniert mit jeder Programmiersprache, die testbar ist und deren Arbeit sich in Pull Requests organisieren lässt. Die konkreten Verifikationsbefehle (Typprüfung, Linting, Tests) tauschst du gegen die deines Projekts aus, die Struktur bleibt gleich.
In meinen eigenen Projekten setze ich diesen Workflow auf einem TypeScript-Stack ein, unter anderem beim Aufbau der Bau-Plattform Baudoku. Genauso ließe er sich für Python, Go oder Rust verwenden. Entscheidend ist nicht die Sprache, sondern dass jede Phase ein prüfbares Ergebnis liefert: eine Spec, die man bewerten kann, einen Plan mit Testschritten und einen Diff, den ein zweites Modell gegenlesen kann.
Ersetzt autonome Feature-Entwicklung den Entwickler?
Nein. Sie verschiebt den Aufwand, sie entfernt ihn nicht. Statt Zeile für Zeile zu tippen, schreibst du das Feature-File, bewertest Reviews, entscheidest bei strittigen Befunden und verantwortest den finalen Merge. Die anspruchsvollen Tätigkeiten (sauber spezifizieren, Trade-offs abwägen, Qualität beurteilen) bleiben beim Menschen.
Was wegfällt, ist die mechanische Fließbandarbeit: Boilerplate schreiben, Tests von Hand aufsetzen, Routine-Reviews durchklicken. Was bleibt und sogar wichtiger wird, ist das Urteilsvermögen. Ein schlechtes Feature-File führt zu schlechtem Output, egal wie gut die Modelle sind. Wer diesen Workflow nutzt, wird weniger Mechaniker und mehr Architekt. Mehr zu diesem Rollenwandel und zu praxistauglichen KI-Setups findest du in meinen Beiträgen zur KI-Automatisierung für Unternehmen und zum Aufbau einer eigenen KI für Unternehmen.
Häufig gestellte Fragen (FAQ)
Was bedeutet autonome Feature-Entwicklung? Du beschreibst ein Feature einmal als Feature-File, und zwei KI-Modelle spezifizieren, planen, programmieren, testen und reviewen es eigenständig. Am Ende stehen geprüfte Pull Requests, die du nur noch mergst.
Welche Tools brauche ich für diese Methode? Claude Code als Builder und das Codex-Plugin als Reviewer. Voraussetzung: ChatGPT-Abo oder OpenAI API Key, Node.js ab 18.18 und die Codex CLI. Optional Google Stitch oder Figma für das Feature-File.
Warum reichen zwei Review-Runden für Spec und Plan? Zwei Runden fangen die meisten echten Lücken ab, danach sinkt der Nutzen stark. Das Limit verhindert Endlosschleifen. Der PR-Review läuft dagegen, bis keine Issues mehr offen sind.
Kann ein einzelnes KI-Modell beide Rollen übernehmen? Technisch ja, in der Praxis nicht empfehlenswert. Ein Modell, das eigenen Code im selben Kontext reviewt, übernimmt frühere Annahmen ungeprüft (Context Rot). Zwei verschiedene Modelle finden mehr Probleme.
Wie generiere ich ein Feature-File aus einem Figma- oder Stitch-Design? Du baust das UI in Google Stitch oder Figma und übergibst es der KI, etwa per Export oder über den MCP-Server von Stitch. Die KI leitet daraus ein Feature-File ab, das anschließend zweimal reviewed wird.
Ist die Methode an einen bestimmten Tech-Stack gebunden? Nein. Der Ablauf aus Feature-File, Spec, Plan, TDD und PR-Review ist stackunabhängig und funktioniert mit jeder Sprache, die testbar ist und in Pull Requests organisiert wird.
Ersetzt autonome Feature-Entwicklung den Entwickler? Nein. Sie verschiebt den Aufwand vom Tippen zum Spezifizieren, Prüfen und Entscheiden. Du schreibst das Feature-File, bewertest Reviews und verantwortest den finalen Merge.
Wie löst ein einziger Satz den ganzen Workflow aus? Du legst den Ablauf als Markdown-Datei im Repository ab und verlinkst sie aus der Instruktionsdatei deines Agenten (CLAUDE.md oder AGENTS.md). Der Agent liest diese Instruktion bei jedem Start und folgt dem Ablauf.
Warum meldet ein Code-Review meiner Spec null Fehler? Weil eine Spec aus Text besteht und ein Code-Reviewer nach Code-Defekten sucht. Findet er keinen Code, meldet er null Issues. Nutze für Spec und Plan ein Design-Review mit Fokus-Text.
Über den Autor: Nikolaus Schauersberger ist Software-Entwickler mit über 13 Jahren Erfahrung und Fokus auf KI-Automatisierung. Er baut unter anderem die Bau-Plattform Baudoku. Mehr unter schauersberger.com.